|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
|
// Implicit과 공통되는 선언부 생략
static char *lastplacedP;
static size_t lastplacedsize;
int mm_init(void) // Implicit과 동일
static char *extend_heap(size_t words) // Implicit과 동일
static char *coalesce(char *bp)
{
// 상단 병합부 생략
// 병합한 새 블록은 다음 find fit의 대상이 될 수도 있고 아닐 수도 있다
// 새 블록의 size가 lastplacedsize보다 작다면, lastplacedP를 bp로 갱신해도 fit이 불가능하다
// 기존 lastplacedP의 위치까지 연산력을 낭비하며 이동할 것
// 따라서 size가 lastplacedsize보다 큰 경우에만 lastplacedP를 갱신한다
if (size > lastplacedsize)
{
lastplacedP = bp;
}
return bp;
}
void mm_free(void *bp) // Implicit과 동일
static char *find_fit(size_t asize)
{
char *bp;
for (bp = lastplacedP; getsize(headerP(bp)) > 0; bp = nextblockP(bp))
{
if (!getalloc(headerP(bp)) && (getsize(headerP(bp)) >= asize))
{
return bp;
}
}
// asize가 lastplacedsize 이상이라면 lastplacedP 이전은 탐색해도 어차피 없을 것
// (이전 탐색에서 asize보다 큰 lastplacedsize로 탐색했는데 lastplacedP까지 갔으므로)
// asize가 lastplacedsize 보다 작을 때에만 lastplacedP 이전을 탐색한다
if (asize < lastplacedsize)
{
for (bp = heapP; bp < lastplacedP; bp = nextblockP(bp))
{
if (!getalloc(headerP(bp)) && (getsize(headerP(bp)) >= asize))
{
return bp;
}
}
}
return NULL;
}
static void place(char *bp, size_t asize) // lastplacedP, lastplacedsize를 갱신하는것 외 동일
{
size_t csize = getsize(headerP(bp));
size_t surplus = csize - asize;
if (surplus < Dsize*2)
{
put(headerP(bp), pack(csize, 1));
put(footerP(bp), pack(csize, 1));
lastplacedsize = csize;
}
else
{
put(headerP(bp), pack(asize, 1));
put(footerP(bp), pack(asize, 1));
bp = nextblockP(bp);
put(headerP(bp), pack(surplus, 0));
put(footerP(bp), pack(surplus, 0));
lastplacedsize = asize;
}
lastplacedP = bp;
}
void *mm_malloc(size_t size) // Implicit과 동일
void *mm_realloc(void *oldP, size_t newsize) // Implicit과 동일
|
cs |
Implicit 가용 리스트를 그대로 쓰지만, 가용 블록을 탐색하는 알고리즘을 next fit으로 바꾼 코드
현재의 탐색은 이전 탐색보다 size가 클 수도 있고, 작을 수도 있다.
만약에 이전 탐색보다 size가 크다면, heap의 처음 ~ 이전 탐색시 할당한 위치까지의 빈 블록은 fit이 불가능함을 탐색하지 않아도 알 수 있다. (size보다 작은 이전 탐색에서도 할당하지 못했으므로)
따라서 마지막으로 할당된 위치를 전역변수로 관리하고, 그 위치에서 탐색을 시작하는 것이 확률적 접근에서 더 좋은 성능을 낼 것이다.
전역변수로 기록된 값과 현재의 입력값의 컨디션에 따라 탐색해봤자 fit되는 블록이 없을 구간이 있을텐데, 이를 고려하여 연산에서 배제하는 것이 next fit의 아이디어이다.
바로 생각나는 부분들은 배제를 했는데 더 있는지는 모르겠다.
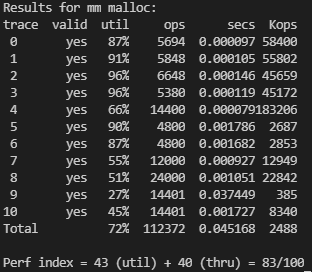
성능은 first fit에 비하면 확실히 좋아졌다.
'Week 05 ~ 07 : 전산학 프로젝트 > SW정글 Week 06 : Malloc Lab' 카테고리의 다른 글
| [Malloc Lab] 5. 성능 개선을 위한 몇가지 최적화 (0) | 2021.12.15 |
|---|---|
| [Malloc Lab] 4. Explicit, pointer 기록을 이용한 malloc 구현 (0) | 2021.12.14 |
| [Malloc Lab] 3. Explicit, vector 기록을 이용한 malloc 구현 (0) | 2021.12.14 |
| [Malloc Lab] 1. Implicit, first fit을 이용한 malloc 구현 (0) | 2021.12.14 |
| Week 06 : Malloc Lab / PLAN (0) | 2021.12.13 |