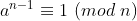밀러-라빈 알고리즘(https://uneducatedjungler.tistory.com/121)에서 이어지는 글 폴라드 로 알고리즘은 입력된 정수 n의 랜덤한 인수를 뽑아내는 알고리즘이다. 정리에 앞서 거칠게 폴라드 로를 요약하자면 아래와 같다. "n과 d의 공약수를 발견할 때까지 d에 유사난수를 대입한다" 얼핏 보면 n에 1부터 차례대로 나눠보는 것과 다름없는 굉장히 무식해보이는 방법같아 보이지만, 실제로는 의외로 빠르다. 그 이유는 생일 역설을 보면 알 수 있다. 생일 역설 (https://ko.wikipedia.org/wiki/%EC%83%9D%EC%9D%BC_%EB%AC%B8%EC%A0%9C) 생일은 366일이라는 한정된 range를 갖고 있다. 따라서 367명 이상이 있으면 반드시 생일이 같은 ..